Hierarchical Attention Network For Multilabel Classification (Detailed Case study)
Multilabel Text Classification Using Custom Embeddings in Keras.¶
Traditionally, classification problems are either formulated as -
- Binary Classification problems - where each training example belongs to either a positive or a negative class.
- Multiclass Classification problem - where each training example belongs to one of the 'k' classes.
In this article, we shall explore a new problem statement -
Multilabel Classification Problem -¶
- In many real world data applications, often we encounter scenarios where each data point belongs to multiple classes.
- Suppose you are working for Recruiting Firm which receives thousands of Resumes each day. You are tasked with the problem of tagging each resume with relevant set of skills which hiring committee cares about.
- In such a scenario, it is possible to have a candidate who possesses 'leadership' skills as well as 'coding' skills.
- Such a setup requires you to solve a multilabel classification problem.
The following sections will cover -
- Data Description,
- Data Cleaning.
- Encoding Labels.
- Defining a custom Embedding Layer with keras.
- Defining Loss Function and Evaluation Metric for Multilabel Classification
- Model Building
- Training a model
- Inference.
- Final Comments and References.
Let's start by importing a whole bunch of python libraries that we will need for successful implementation of our algorithm.
import os
import json
import re
import string
import codecs
from operator import itemgetter
import numpy as np
import pandas as pd
import keras.backend as K
from keras.layers import (Dense, Conv1D, Activation,
BatchNormalization, MaxPooling1D, Dropout, Flatten, GlobalMaxPool1D, Bidirectional,
LSTM, GRU, Lambda, Concatenate, Dot, Reshape, TimeDistributed)
from keras.models import Model, Input
from keras.preprocessing.text import Tokenizer, one_hot, text_to_word_sequence
from keras.preprocessing import sequence
from keras.preprocessing.sequence import pad_sequences
import keras
from keras.layers.embeddings import Embedding
from keras import optimizers, regularizers
from keras.optimizers import SGD
from keras.utils import to_categorical
from keras.regularizers import l1, l2
from nltk.corpus import stopwords
from nltk.stem import WordNetLemmatizer
import nltk
from nltk import word_tokenize, sent_tokenize
import sklearn
from sklearn.utils import shuffle
from sklearn.preprocessing import MultiLabelBinarizer
from IPython.core.interactiveshell import InteractiveShell
InteractiveShell.ast_node_interactivity = "all"
import matplotlib.pyplot as plt
%matplotlib inline
from IPython.display import HTML
display(HTML('<style>.prompt{width: 0px; min-width: 0px; visibility: collapse}</style>'))
display(HTML("<style>.container { width:100% !important; }</style>"))
batch_size = 12
MAX_NB_WORDS = 300000
weight_decay = 1e-4
latent_dim = 300
Data Description -¶
For implementing a multilabel classifier, we shall be using the "DBPedia Hierarchical Classes dataset" dataset from Kaggle.
Context -¶
- DBpedia (from "DB" for "database") is a project aiming to extract structured content from the information created in Wikipedia.
- This is an extract of the data that provides taxonomic, hierarchical categories ("classes") for 342,782 wikipedia articles.
- There are 3 levels, with 9, 70 and 219 classes respectively. A version of this dataset is a popular baseline for NLP/text classification tasks.
This version of the dataset is much tougher, especially if the L2/L3 levels are used as the targets.
The Dataset consists of the following columns -
- text - a free text column which describes the entity.
- l1 - Base label in the hierarchy.
- l2 - Intermediate label in the hierarchy.
- l3 - Top level label in the hierarchy.
There can be multiple tags associated with each entity making it a multilabel classificatiopn problem.
### load training data
data = pd.read_csv('./data/dbpedia/DBPEDIA_train.csv',
encoding = "utf-8", names = ['raw_text', 'l1', 'l2','l3'],header = 0)
display(data.head())
Data Cleaning -¶
In this section, we shall perform some basic preprocessing on our raw text data using following techniques -
- merge title and synopsis data columns for better handling. We shall refer this column as raw_text
- Split comma separated tags for each movie.
- Remove punctuation and stopwords from raw_text.
- Lemmatize raw_text - Lemmatization usually refers to doing things properly with the use of a vocabulary and morphological analysis of words, normally aiming to remove inflectional endings only and to return the base or dictionary form of a word, which is known as the lemma . For more information on lemmatization refer to the stanford notes.
en_stopwords = set(stopwords.words('english'))
punctuations_filter = string.punctuation.replace(".", "")
print(punctuations_filter)
regex = re.compile('[%s]' % re.escape(punctuations_filter))
puncts_trans = string.maketrans("", "")
lemmatizer = WordNetLemmatizer()
def get_cleaned_string(raw_string):
cleaned_text = regex.sub('', raw_string).lower()
tokens = [lemmatizer.lemmatize(word) for word in nltk.word_tokenize(cleaned_text) if word not in en_stopwords]
sentence = " ".join(tokens)
return sentence
data['cleaned_text'] = data['raw_text'].apply(get_cleaned_string)
Train Test Split -¶
In this section, we shall split our data into 3 subsets -
a. Training data - This data will be used for training our classifier my minimizing the overall loss.
b. Validation data - The Validation data will help in selecting hyper-parameters. Since this data is not explicitly used for training the model, validation data also helps in reducing overfitting.
c. Test Data - We shall use test data to estimate model's performance on OOB (out-of-bag) data points.
Since there is no off the shelf function in sklearn or keras that splits dataset into 3 different subsets, We shall leverage the train_test_split function by making a call to it twice.
raw_train_data, test_data = sklearn.model_selection.train_test_split(data, test_size = 0.03)
train_data, validation_data = sklearn.model_selection.train_test_split(raw_train_data, test_size = 0.03)
train_data = train_data.reset_index(drop= True)
validation_data = validation_data.reset_index(drop= True)
test_data = test_data.reset_index(drop= True)
print("Training data has %d datapoints"%len(train_data))
print("Validation data has %d datapoints"%len(validation_data))
print("Test data has %d datapoints"%len(test_data))
display(train_data[['cleaned_text', 'l1', 'l2', 'l3']].head())
Label Encoding -¶
- In order to train a classifier, we need to convert the string tags into a vector of 1s and 0s.
- There are about 71 tags in the dataset.
- Therefore, for each datapoint, we need to construct a 1 x 71 dimensional vector with each bit in the vector representing a tag.
- Since datapoint can have multiple tags, the target label will consist of 1s at all indices corresponding to the target tag attached to the datapoint.
To accomplish this, we shall train a MultiLabelBinarizer.
labelEncoder_model = MultiLabelBinarizer()
labelEncoder_model.fit(data[['l1', 'l2', 'l3']].values)
unique_classes = labelEncoder_model.classes_
print("sample classes are %s"%list(unique_classes)[:10])
Custom Embedding Layer -¶
- Embedding layer in keras is responsible of representing the input sequence of text with a vector of a size defined in the model.
- one of the most adopted techniques while working with text is to train a tfidf vectorizer followed by a Dimensionality Reduction technique (PCA, Random Projections, etc) .
- The embedding layer in keras facilitates the execution of sequence mentioned above while training a classifier.
- It is also possible to derive weights from a pretrained model like word2vec or gloVe. However, in this article we shall focus on training a custom Embedding layer.
- The Embedding layer expect a fixed input size of dimensions (batch_size $\times$ max_sequence_length) where max_sequence_length determines the maximum length of input text sequence.
- The Output of Embedding Layer is a matrix of shape batch_size X max_sequence_length X embedding_size.
In order to match the input contract, we shall train a keras Tokenizer using fit_on_texts function. Note that, one can use different techniques to identify the max sequence length. For the sake of this project, we will consider the 90th percentile of the input sequence length distribution.
print("tokenizing input data...")
tokenizer1 = Tokenizer(num_words=MAX_NB_WORDS, lower=True, char_level=False)
tokenizer1.fit_on_texts(train_data['cleaned_text'])
train_data['doc_len'] = train_data['cleaned_text'].apply(lambda sentence: len(sentence.split(' ')))
Attention Mechanism -¶
Before we proceed further, I would like to take a pause and delve into the philosophical and mathematical details of Attention Mechanism.
Why Attention Mechanism ?¶
- Consider a simple spam vs not-spam binary text classification problem where input is a free flowing email text and you would like to predict if it is a spam or not-spam.
- Typically, if you were to decide manually, you invariably look for trigger words (Nigerian Prince, Lottery Winner, No credit check, <suspicious link> , etc) which would hint towards an email being spam.
- These trigger words influence your decision no matter where they appear in text. In other words, subconsciously you end up assigning a higher weight to these trigger keywords which ultimately helps you reach a decision.
- Attention Mechanism tries to replicate a similar behaviour where it attempts to assign a higher weightage to trigger keywords that ultimately helps our model in reaching a decision.
Aren't the likes of GRUs and LSTMs suppose to do something similar?¶
- Well, a typical RNN network suffers from the problem of vanishing gradients. As a result, earlier parts of a temporal data is unable to contribute towards the final decision being made.
- GRUs and LSTMs are able to ameliorate this problem by introducing memory cells and forget gates.
- However, they can remember sequences of 100s but not definitely not 1000s.
- Sure, one can take a Global Max of returned activations and use them to predict classes but a "hard-max" takes the maximum value and forgets everything else.
ENTER ATTENTION MECHANISM !!

- A softmax (Attention weights) gives the probability distribution over each activation at different time steps. Definitely, a distribution is more helpful than a point estimate (Stats 101, right?)
Estimating Attention Weights while training -¶
- Hopefully, the need for an Attention Mechanism is justified in the previous section.
- In this section, let's go over some of the mathematical details to better understand the concept. This will help us while building the network as well.
Let's get to it -¶
- It is evident that these weights are dynamic and hence cannot be pre-computed.
- The following image by WildML summarises the attention mechanism in a block diagram format.
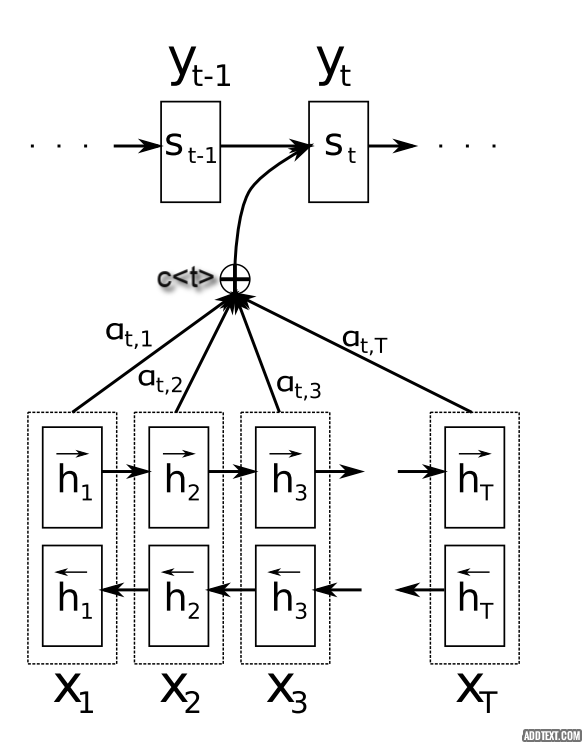
- As seen in the above image, the output at time 't' is a weighted average of weights $\alpha^{<t,t'>}$ where t' = ${1, 2, 3....T_x}$
- $\alpha^{<t,t'>}$ indicates the amount of attention that $y^{<t>}$ should pay to $a^{<t'>}$
- \begin{align}
c^{
} = \sum_{t'=1}^{Tx} \alpha^{
How to compute $\alpha^{<t,t'>}$ ?¶
- Since $\alpha^{<t,t'>}$ are weights at time t representing the probability distribution of attentions, a good way to model them would be to use Softmax (If you guessed it, be proud of yourselves !!)
Let's define -
\begin{align} \alpha^{
It is easy to conclude that where model should pay attention is dictated by the values of $<e^{t,t'}>$
Where to pay attention depends not only on hidden states ($a^{<t'>}$) but also on where we are in the output ($s^{<t-1>}$) sequence of length $T_y$.
However, we don't know the function that maps hidden states and current output to $e^{<t,t'>}$. Hence we shall determine the function using a small neural network.
In text classification, the output steps are limited to 1. This simplifies our problem statement. The magnified block diagram for attention mechanism is as follows -
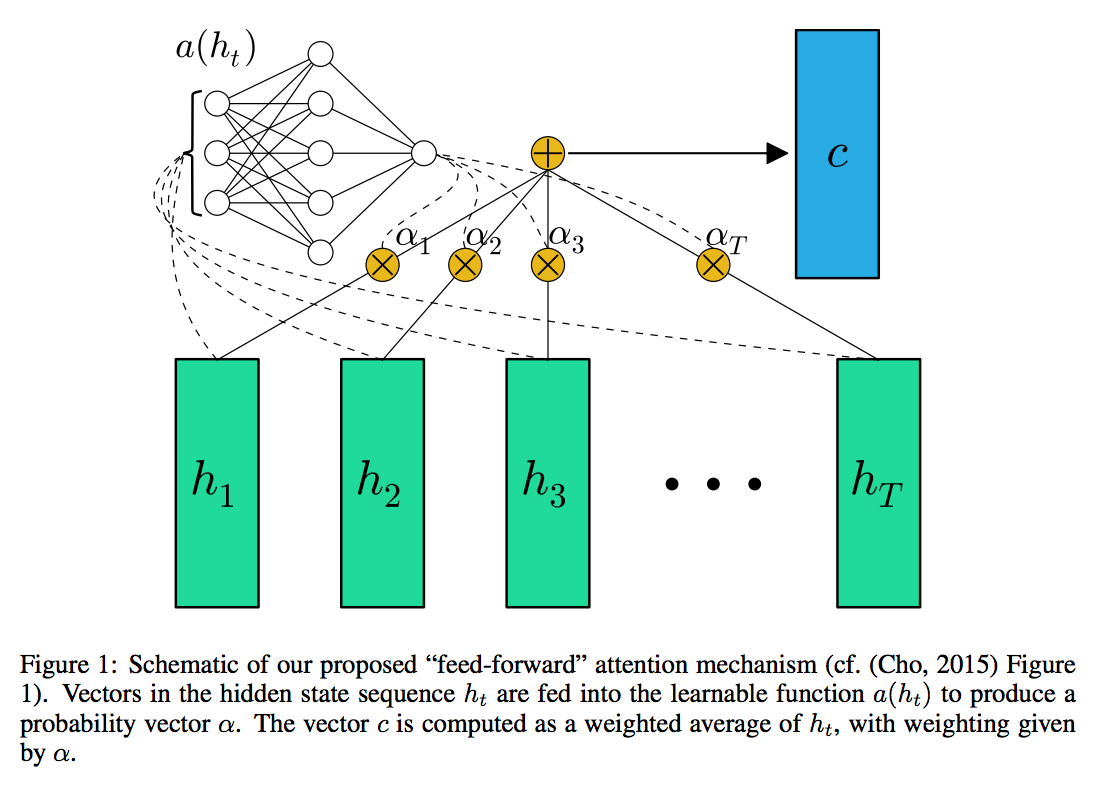
Hierarchical Attention Network -¶
- With the basics around attention network chalked out, let's take this a notch higher.
- Hierarchical Attention Networks were introduced by Zichao Yang, Diyi Yang, Chris Dyer, Xiaodong He, Alex Smola, & Eduard Hovy at Carnegie Melon in association with Microsoft.
- The proposed model exploits the herarchical structure in documents.
- Each document can be viewed as a group sentences with each sentence as collection of words.
- The block diagram of the architecture is as follows -
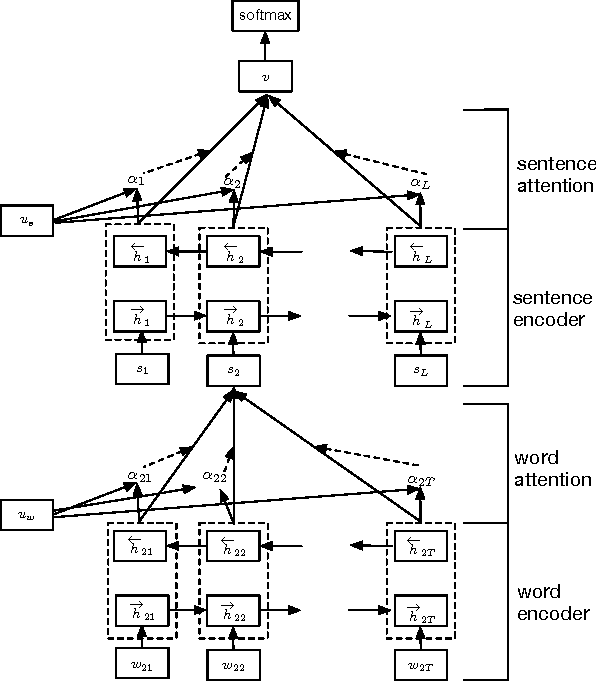
- The model represents a document representation by building a representation of sentences which are then aggregated.
- Further, the model also represents each sentence by building a representation of words.
- This takes into account the fact that words as well as sentences are differentially important based on context.
The original paper can be found here. Do take some time to read it.
Data Wrangling -¶
- It is now time to implement the ideas studied in earlier sections.
- We start by pre-processing our input data.
- The raw input data consists of paragraphs of textual information of dimensions m $\times$ 1.
- In the next section, we simply convert of 1D data into 2D. The new dimensions will be $m \times n_{sent} \times n_{words}$ where m is the number of training examples, $n_{sent}$ is the maximum number of sentences in each training example and $n_{words}$ is the maximum number of words in a sentence.
tot_sents = []
num_sents = []
len_sent = []
for text_val in train_data['cleaned_text']:
ind_sentences = sent_tokenize(text_val)
tot_sents.append(ind_sentences)
num_sents.append(len(ind_sentences))
for sent in ind_sentences:
len_sent.append(len(word_tokenize(sent)))
max_sent_len = int(np.percentile(len_sent, 98))
max_num_sent = int(np.percentile(num_sents, 95))
print("Max sentences capped to %f"%max_num_sent)
print("Max sentence length capped at %f"%max_sent_len)
train_data_np = np.zeros((len(train_data['cleaned_text']), max_num_sent, max_sent_len), dtype='int32')
for i, sentences in enumerate(tot_sents):
for j, sent in enumerate(sentences):
if j< max_num_sent:
wordTokens = text_to_word_sequence(sent)
k=0
for _, word in enumerate(wordTokens):
try:
if k<max_sent_len and tokenizer1.word_index[word]<MAX_NB_WORDS:
train_data_np[i,j,k] = tokenizer1.word_index[word]
k=k+1
except:
pass
val_sents = []
for text_val in validation_data['cleaned_text']:
ind_sentences = sent_tokenize(text_val)
val_sents.append(ind_sentences)
val_data_np = np.zeros((len(validation_data['cleaned_text']), max_num_sent, max_sent_len), dtype='int32')
for i, sentences in enumerate(val_sents):
for j, sent in enumerate(sentences):
if j< max_num_sent:
wordTokens = text_to_word_sequence(sent)
k=0
for _, word in enumerate(wordTokens):
try:
if k<max_sent_len and tokenizer1.word_index[word]<MAX_NB_WORDS:
val_data_np[i,j,k] = tokenizer1.word_index[word]
k=k+1
except:
pass
word_index = tokenizer1.word_index
vocab_size = len(tokenizer1.word_index) +1
print("Vocab size - %d"%vocab_size)
Transfer Learning -¶
- To expedite the training process, we shall piggy back on pre-trained gloVe models.
- The process of building Embedding matrix is pretty standard.
#load embeddings
print('loading word embeddings...')
embeddings_index = {}
f = codecs.open(os.path.join('.', 'data', 'glove_pretrained' ,'glove.42B.300d.txt'), encoding='utf-8')
for line in f:
values = line.rstrip().rsplit(' ')
word = values[0]
coefs = np.asarray(values[1:], dtype='float32')
embeddings_index[word] = coefs
f.close()
print('found %s word vectors' % len(embeddings_index))
#embedding matrix
print('preparing embedding matrix...')
words_not_found = []
nb_words = min(MAX_NB_WORDS, vocab_size)
embedding_matrix = np.zeros((nb_words, latent_dim))
for word, i in word_index.items():
if i >= nb_words:
continue
embedding_vector = embeddings_index.get(word)
if (embedding_vector is not None) and len(embedding_vector) > 0:
# words not found in embedding index will be all-zeros.
embedding_matrix[i] = embedding_vector
else:
words_not_found.append(word)
print('number of null word embeddings: %d' % np.sum(np.sum(embedding_matrix, axis=1) == 0))
def prepare_training_generators(train_x,train_y, chunk_size = 5, channel_orientation = "channels_first"):
'''
This function generates mini batches of training data in the form of an iterator.
inputs:
train_df: pandas dataframe of training data.
len_unique_classes - integer value highlighting the number of unique target labels in training data.
chunk_size - integer value highlighting the mini batch siz. The default value is set to 16
channel_orientation - A string values used to represenattion the channel orientation of images to be read.
output:
iterator of text_data, image_data and output label
'''
indices = range(len(train_x))
index_tracker = 0
while True:
batch_indices = indices[index_tracker : index_tracker+chunk_size]
text_x = train_x[batch_indices]
y_le = labelEncoder_model.transform(train_y.loc[batch_indices, ['l1', 'l2', 'l3']].values)
index_tracker += chunk_size
if index_tracker >= len(train_x):
index_tracker = 0
np.random.shuffle(indices)
yield text_x,y_le
Loss Function and Evaluation metric -¶
Loss Function -¶
- A cross entropy loss for C classes and m training examples is defined as -
- Typically a Binary classification problem uses a sigmoid activation in the final layer of the neural network.
- The sigmoid function for pre-activations $z$ is defined as -
Where,
The cross entropy loss function for binary classification can hence be written as - \begin{align} BCE & = - \sum_{i = 1}^{m} \sum_{j= 1}^{2} y_ilog(\hat{y_i}) \\ & = - \sum_{i = 1}^{m} y_i log(\hat{y_i}) + (1- y_i)log(1 - \hat{y_i}) \end{align}
- For multilabel classification we shall assume that each label as an independent Binomial Random Variable.
- As a result of this assumption, a loss of Binary loss function makes much more sense than a categorical cross entropy function.
- Lastly, by the assumption of independence, since the probability that a data point belongs to class i is independent of whether of class j, the activation in the final layer of the network has to be "sigmoid" and not "softmax".
For a multilabel classification problem, various different loss function can also be used. Check them out at the following links for more information.
- Multilabel Classification - Label Dependence, Loss Minimization and Reduction Algorithms by Krzysztof Dembczy´nski
- Distance for Binary Variables
- Approaches for the Improvement of the Multilabel Multiclass Classification with a huge Number of Classes by Martha Tatusch
Evaluation Metric -¶
- Typically, a standard metric for classification like accuracy can suffice.
- However, it can often be misleading when target labels have only a small subset which is positive. In such cases, accuracy is often over-estimated.
- To overcome this problem, we shall be using a custom loss function defined by Matthew R. Boutell in Learning multi-label scene classification
- Please find below a snippet from the paper which describes the $\alpha evaluation$ metric -

def softmax_over_time(x):
assert(K.ndim(x) > 2)
e = K.exp(x - K.max(x, axis=1, keepdims=True))
s = K.sum(e, axis=1, keepdims=True)
return e / s
def check_nonzero(y_true,y_pred):
"""
Custom metric
Returns sum of all embeddings
"""
return(K.sum(K.cast(y_pred > 0.4, 'int32')))
def custom_score(y_true, y_pred):
"""
score reference - https://www.rose-hulman.edu/~boutell/publications/boutell04PRmultilabel.pdf
more resources -
1. Distance between binary variables - https://people.revoledu.com/kardi/tutorial/Similarity/BinaryVariables.html
2. jaccard co-efficient (intersection over union) - https://people.revoledu.com/kardi/tutorial/Similarity/Jaccard.html
"""
y_true = K.cast(y_true, 'int32')
y_pred = K.cast(K.round(y_pred), 'int32')
neg_y_true = 1 - y_true
neg_y_pred = 1 - y_pred
alpha = K.constant(1, 'float32')
beta = K.constant(0.75, 'float32')
gamma = K.constant(1, 'float32')
tp = K.cast(K.sum(y_true * y_pred), 'float32')
fp = K.cast(K.sum(neg_y_true * y_pred), 'float32')
fn = K.cast(K.sum(y_true * neg_y_pred), 'float32')
score = 1 - ((beta * fn + gamma * fp) / (fn+ fp +tp + K.epsilon()))
return score
Building HAN Model -¶
- In order to build a Hierarchical Attention network, we will split it into two models for better visibility, debugging and code management.
- First, we define a "word attention model" which takes a sentence as input and return activations based an attention mechanism.
- Next we design a "sentence attention model" which is responsible for representing attention mechanism for each sentence at the input.
- Note that, we shall be using TimeDistributed layer provided by keras to extract word attention representation for each sentence at the input. The TimeDistributed layer ensures that same weights are applied to each input in the sequence.
def word_encoder(text_input_shape):
inp = Input(shape=text_input_shape)
x= Embedding(embedding_matrix.shape[0], embedding_matrix.shape[1],
weights=[embedding_matrix], trainable=False)(inp)
# x = Embedding(vocab_size, latent_dim)(inp)
x = BatchNormalization()(x)
h = Bidirectional(GRU(128, return_sequences=True, recurrent_dropout=0.2, dropout=0.2))(x)
## FCNN for estimating attention weights.
u = Dense(256)(h)
u = BatchNormalization()(u)
u = Activation('tanh')(u)
u = Dense(1)(u)
u = BatchNormalization()(u)
u = Activation(softmax_over_time)(u)
## weighted average of attention weights and GRU output sequence for words.
s = Dot(axes=1)([u, h])
s = Flatten()(s)
model = Model(inputs=inp, outputs=s)
word_attention_weights_model = Model(inputs = inp, outputs = u)
model.summary()
return model, word_attention_weights_model
def sent_encoder(word_encoder, text_input_shape=(11, 33), classes = 6):
inp = Input(shape=text_input_shape)
x = TimeDistributed(word_encoder)(inp)
x = BatchNormalization()(x)
h = Bidirectional(GRU(32, return_sequences=True, recurrent_dropout=0.2, dropout=0.2))(x)
## FCNN for estimating attention weights.
u = Dense(128)(h)
u = BatchNormalization()(u)
u = Activation('tanh')(u)
u = Dense(1)(u)
u = BatchNormalization()(u)
u = Activation(softmax_over_time)(u)
## Weighted average of attention and sentence representation sequencs.
s = Dot(axes=1)([u, h])
s = Flatten()(s)
## Note that the activation for final layer is sigmoid and softmax.
x = Dense(classes, activation="sigmoid")(s)
model = Model(inputs=inp, outputs=x)
attention_weights_model = Model(inputs=inp, outputs=u)
opt = keras.optimizers.Adam(lr=0.01, beta_1=0.9, beta_2=0.999, epsilon=None, decay=0.0, amsgrad=False)
## Note that the loss function is 'binary_crossentropy'
model.compile(loss='binary_crossentropy', optimizer='adam', metrics=[custom_score, check_nonzero])
model.summary()
return model, attention_weights_model
word_encoder_model, word_attention_model = word_encoder(text_input_shape=(max_sent_len, ))
text_only_model, sent_attention_weights_model = sent_encoder(word_encoder_model, text_input_shape =(max_num_sent, max_sent_len) ,classes=len(labelEncoder_model.classes_))
tboard = keras.callbacks.TensorBoard(log_dir='./logs', histogram_freq=0, batch_size=batch_size, write_graph=True, write_grads=False,
write_images=False, embeddings_freq=0, embeddings_layer_names=None, embeddings_metadata=None, embeddings_data=None)
validation_data_gen = prepare_training_generators(val_data_np, validation_data, chunk_size = batch_size )
train_data_gen = prepare_training_generators(train_data_np, train_data, chunk_size = batch_size)
history3 = text_only_model.fit_generator(train_data_gen,
steps_per_epoch=np.ceil(len(train_data) / batch_size),
epochs=5,
validation_data = validation_data_gen,
validation_steps = np.ceil(len(validation_data) / batch_size),
verbose=1, callbacks=[tboard])
Training Analysis -¶
- It can be seen that the loss is decreasing consistently across epochs.
- The custom_score keeps getting better.
- The custom_score and loss on validation dataset is comparable with training phase which indicates that the model is not overfitting.
Investigating Attention Mechanism -¶
- In order to gain more insights on how our model is training, let us perform a quick analysis of how model is estimated weights and which words are actually being paid attention to while predicting multilabel classes.
- To facilitate this analysis, we have tapped our original models to spit out attention weighted activations.
- Based on these activations, we can back trace the word in the input which are influencing the final decision.
Without much further a do, lets jump into the implementation !!
sugg_num = 190
tokenized_sentences = sent_tokenize(validation_data['cleaned_text'].iloc[sugg_num])
true_labels = validation_data[['l1', 'l2','l3']].iloc[sugg_num].values
print("True labels are %s"%true_labels)
for sent_num in range(len(tokenized_sentences)):
word_attention_vector = word_attention_model.predict(val_data_np[sugg_num:sugg_num+1, sent_num, :])[0][:, 0]
sorted_indices = np.argsort(word_attention_vector)[::-1]
sorted_weights = np.sort(word_attention_vector)[::-1]
tokenized_words = word_tokenize(tokenized_sentences[sent_num])
padded_tokenized_words = tokenized_words + ['<dummy>'] * (max_sent_len - len(tokenized_words))
top_words = itemgetter(*sorted_indices)(padded_tokenized_words)
short_listed_words = [(word, attention_weight) for word, attention_weight in zip(top_words, sorted_weights) if attention_weight > 0.15]
print("Sentence is \n %s"%tokenized_sentences[sent_num])
print("Focused words are \n %s"%short_listed_words)
print("*************************************************")
Results and Final Comments -¶
VOILA !!! We can now trace the path of how the model is reaching its decision.
- As seen from the output printed on the console, the input text is describing a wrestling event.
- The model is iterating over different sentences and words with more "Attention" are being printed.
- The model is able to correctly assign weights in each word which is indicative of wrestling despite having other words like philadelphia, pennsylvania, and unites states which hints towards "Place" as a potential label.
- By assigning a lower weights to words that are not so important in the overall context of the document, the model is more robust and accurate.
Final Comments -¶
- To scope down the problem statement, the output sequence in our problem definition has a size 1.
- Hence it suffices to ignore the previous decoder states while estimating attentions at time t.
- In other words, $T_y$ in our case is 1 which largely simplifies the implementation.
- The code will change if we are tasked with a use case that involves a temporal output. In such a situation, we will have to account for previous decoder states while estimating attentions.
Finally, this article covers a lot of new concepts viz. -
a. Formulation of Multilabel classification
b. Attention Mechanism
c. Hierarchical Attention Network
d. Loss function and Activations for multilabel classification problem
e. custom loss function.
Some of these may not be easy to digest. Feel free to reach out to me if you have any queries or would like to brainstorm ideas.